UUIDs vs ULIDs For Better Write Performance At Scale
UUIDs vs ULIDs For Better Write Performance At Scale
In this article, we will be discussing the usage of keys as unique identifiers in a distributed relational database setup and their impact on write performance.
The use of auto-incremented, non-repeating, sorted integers has been a common practice for defining primary keys in relational databases. This type of key has been successful because it satisfies the two most crucial indexing requirements.
- They are unique, so they can be uniquely identified.
- They are ordered and sortable, so they can be efficiently indexed.
When the database is a monolithic entity, this kind of key is ideal. However, as soon as we decide to scale and move to a distributed setup this is no longer unique, this is because now multiple entities start generating auto-incremented numbers.
Impact on Clustered Indexes During Writes
Before we move on to discuss alternatives to auto-incremented integers as unique identifiers, let’s try to understand how indexes are impacted when relational databases write new data.
Clustered indexes are typically represented in a b-tree data structure. They have several benefits that make them well-suited for usage in clustered indexes.
- Efficient at searching for data: B-trees are designed to be efficient at searching for data, even in large datasets. They use a hierarchical structure that allows for fast traversal of the data, reducing the number of disk I/O operations required to find a specific value.
- B-trees are balanced: B-trees are self-balancing data structures, which means they maintain a balanced tree structure even when data is inserted or deleted. This helps to ensure that the height of the tree remains relatively constant, which improves performance and reduces the risk of data becoming inaccessible.
- B-trees support range queries: B-trees can support range queries which means they can be used to efficiently find all the values that fall within a specified range. This is useful in scenarios where you need to find all the records that fall within a certain range of values for a particular column.
In most cases in relational databases, it is allowed to have only 1 clustered index per table, this is because the physical organization of the data is controlled by the clustered index(by the column(s) the index is created, typically the primary key column).
In MSSQL when writing data to a table the DBMS includes logical and physical writes. A logical write is when data is modified in a page in the buffer cache and marked as dirty. A physical write is when a dirty page is written from the buffer cache to the disk. Since logical writes are not immediately written to disk there can be more than one logical write to a page in the buffer cache as long as the record is intended to be written on that page(determined by the clustered index).
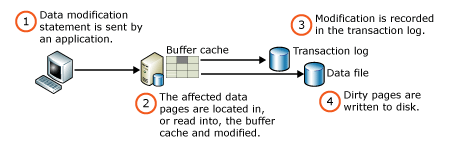 Reference - Writing Pages - SQL Server | Microsoft Learn
Reference - Writing Pages - SQL Server | Microsoft Learn
The DBMS must first determine the correct page to store the new row of data based on the clustered index. To do this, it typically performs a binary search on the index to identify the correct page, once the page is identified it needs to read the page from the disk into the buffer cache, this is only required if the page is not present in the buffer cache.
If the clustered index key adheres to the indexing requirements discussed above then subsequent writes will not require reading pages from the physical disk as in most cases they will be available in the buffer cache due to a previous write in near time reading it into the buffer cache.
As soon as you start using a column that is not ordered(during generation) for a clustered index; It would mean that the data stored in the table requires additional work to be organized in a logical order, which would result in poor write performance.
Alternative Unique Identifiers In a Distributed Environment
Universally Unique Identifier (UUID)
UUIDs are 128-bit long strings that can guarantee uniqueness across space and time. They are widely used to uniquely identify resources. There are several versions of UUIDs, each with a slightly different format. The most generally used UUID version is 4.
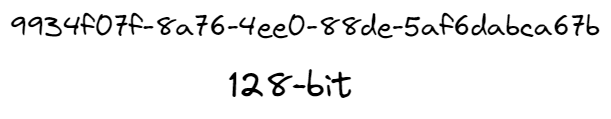 128 bit UUIDV4 string
128 bit UUIDV4 string
A more detailed explanation of UUID can be found in RFC 4122
UUID in a distributed setup allows uniqueness but they are not so good for write performance and here is why;
UUIDs are randomized strings(in most versions) that have no particular order in a generation. When you use them for a clustered index column they need to be ordered and stored. Since they are not ordered(naturally during generation) it requires more I/O to store them on the correct page, this could result in bad write performance in large tables and it could lead to issues like index fragmentation as the data pages may not be in contiguous order.
Universally Unique Lexicographically Sortable Identifier (ULID)
As the title suggests ULIDs are universally unique yet lexicographically sortable identifiers, this is mainly why it is better in write performance at scale compared to UUIDs. ULIDs are a relatively new form of identifiers and still lack widespread native support.
ULID is generated in 2 components,
- Timestamp - 48-bit, integer with the UNIX-time in milliseconds
- Randomness - 80-bit random string
In total, they are a 128-bit long unique yet lexicographically sortable string. ULID is encoded using a combination of binary and base32 characters which results in a more compact 26-character format compared to the 36 characters generated by UUID v4.
More details about ULID can be found in its specification document
Conclusion
In general, we can conclude that ULIDs tend to have the upper hand in write performance( in most cases ) compared to UUIDs, specifically due to the lexicographically sortable nature of ULID.
Thank you for reading this article. I hope to see you at the next one.